혹시 검색어, 채팅 추천이 어떤 원리로 운영되는 지 궁금하신 적 있으신가요?
현실적으로는 프론트, 백, 데이터 프로세싱 등의 다방면의 접근이 필요하지만
그 중 백에서 사용 되는 모델은 트라이(Trie)를 기반으로 하는 것이 많습니다!
이는 트라이의 기능이 검색어를 효율적으로 찾는 것에 도움이 되기 떄문인데요.
우리는 여기서 Basic 한 Trie에 간단히 대해서 알아보겠습니다.
※ 현재 대부분 기업은 Basic이 아닌 훨씬 최적화, 변형된 트라이를 사용합니다.
트라이는 어떤 기능을 하나요?
트라이는 String-search, Substring-search 등을 수행합니다
이 중 String-search 기능을 예로 설명하겠습니다.
우리는 검색어 관리팀이고, n개 낱말의 리스트를 가지고 있다고 합시다.
가진 리스트는 {‘한국은행’, ‘한국만세’, ‘일본’, ‘국장’, ‘국물’,…, ‘국뽕’}
이 때, 한 유저가 기존의 리스트에 ‘국뽕‘이라는 낱말이 있는 지가 궁금합니다.
핵심: 어떻게 하면 리스트에서 이 낱말이 있는 지를 효율적으로 알 수 있을까요??
※ 다음으로 넘어가기 전에 혼자 한 번 고민해봅시다!
Brute-force 하게 해봅시다.
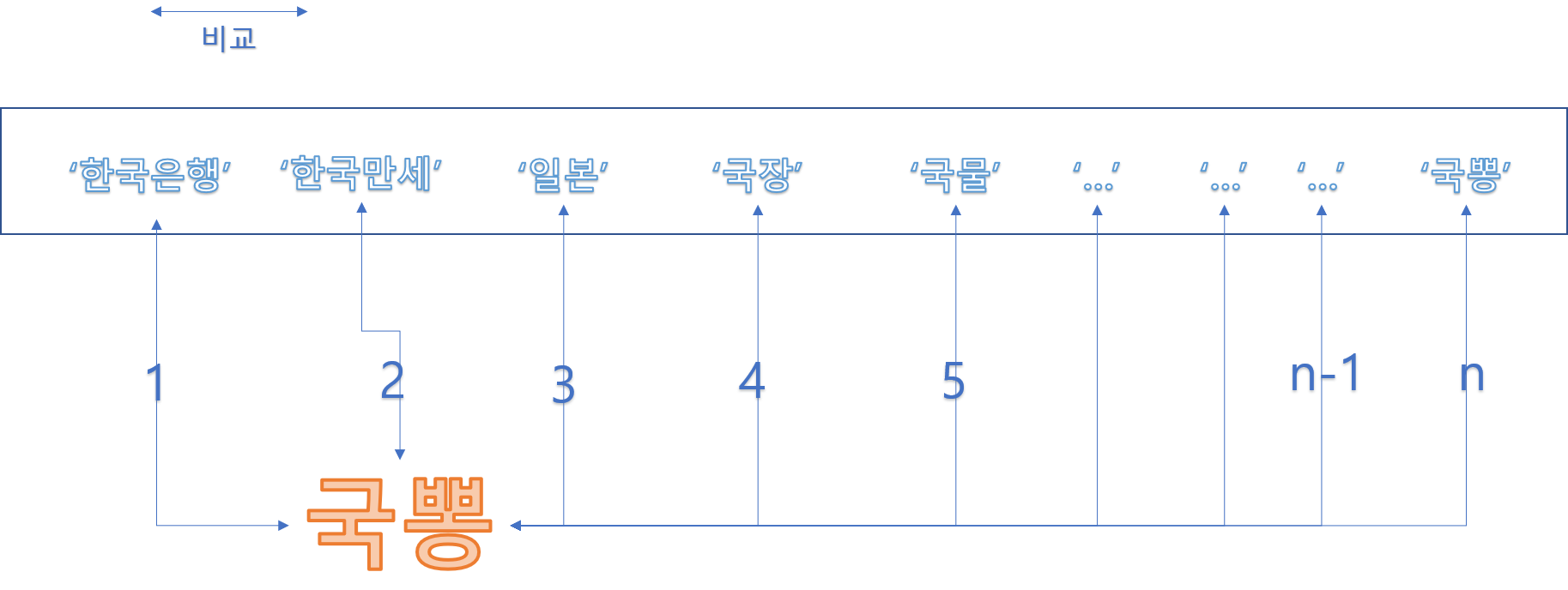
어렵게 생각하지 말고 리스트 안의 것 모두를 우리의 Query인 ‘국뽕’과 하나씩 비교합시다
한국은행과 국뽕을 먼저 비교하고, 다음은 한국만세, 다음은 일본 … 등등
n-1번 까지 있던 모든 글자와는 틀렸다는 것을 확인하고 마지막에서 와서야 겨우
‘국뽕’과 비교를 할 수 있게 되고, 우리는 ‘국뽕’이라는 낱말이 있다는 것을 발견합니다.
이를 시간 효율성에 비추어 생각하면 최악의 경우는 O(N*M)입니다.
이 때, N = 리스트의 길이, M = 쿼리 낱말의 길이입니다.
운좋게, 쿼리가 하나 일 경우에는 이 Brute-force 방법도 참아 줄만 합니다만
만약 궁금한 게 하나의 쿼리가 아니라, [‘국뽕’, ‘일본’, ‘나라’, ..] 처럼 K 개 쿼리의 리스트이면,
각각 쿼리도 똑같은 과정을 거치기에 시간효율성은 O(N* M *K)가 될 것입니다.
위의 시간 효율성은 굉장히 비효율적이며, 현실에서도 적용하기 어렵습니다.
이것을 해결하기 위해서 아래와 같은 트라이(Trie)라는 구조가 고안되었습니다.
트라이의 구조
트라이의 아이디어는 낱말을 하나 하나 글자로 쪼개어 트리로 저장한다입니다.
예를 들면 ‘한국은행’ -> [‘한’, ‘국’, ‘은’, 행’], ‘일본’ -> [‘일’, ‘본’]
과 같이 모두 쪼갠 후에 아래와 같은 과정을 거쳐 트리 형태로 저장을 합니다.
Trie를 만드는 단계:
만드는 단계는 아래와 같은 두 가지 경우로 진행됩니다.
- 낱말을 글자로 쪼갠 후 노드에 공통되는 글자가 있으면 그 글자 노드로 진행
- 낱말을 글자로 쪼꺤 후 노드에 그 글자가 없다면, 글자에 해당되는 노드를 만들고 진행
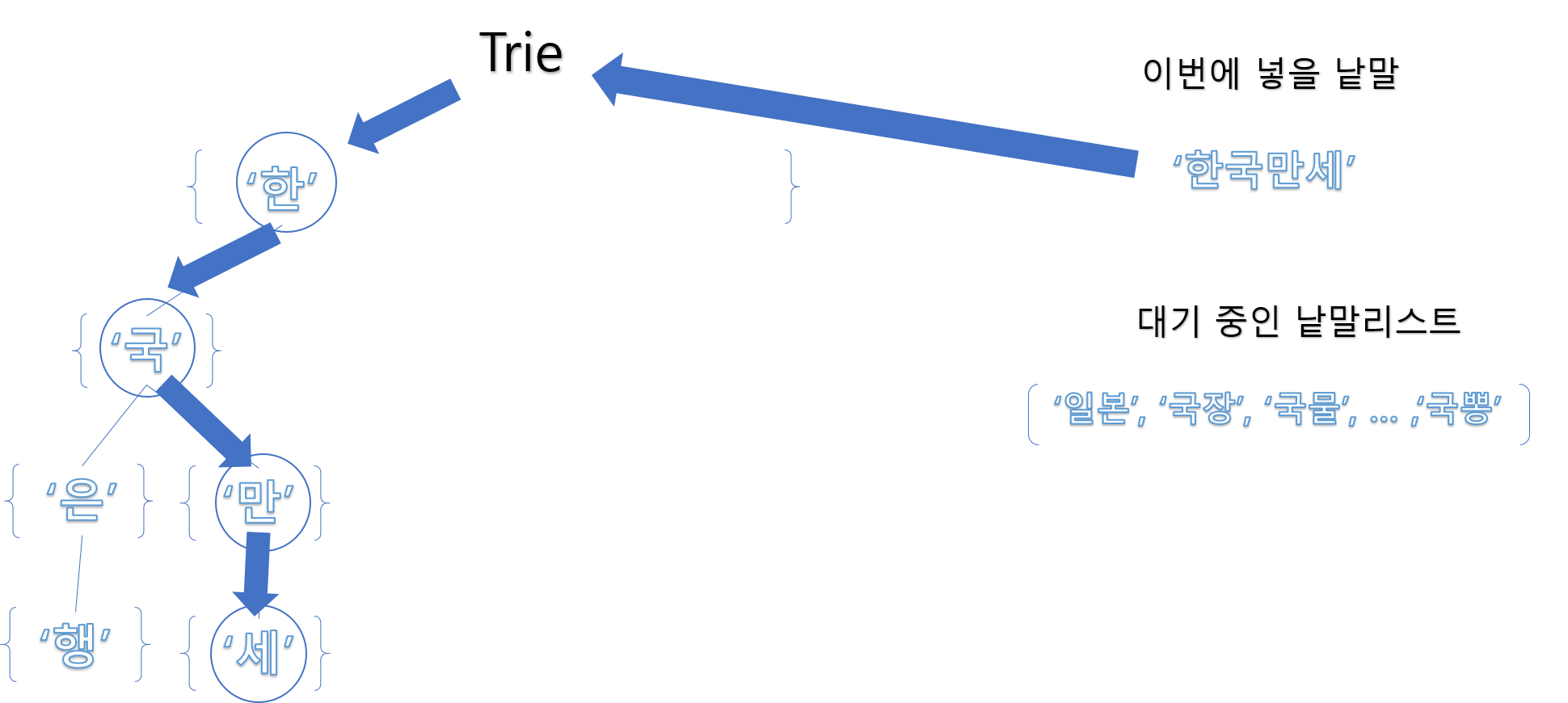
아래는 Trie를 만드는 과정 중 ‘한국만세’ 라는 낱말을 넣는 차례입니다.
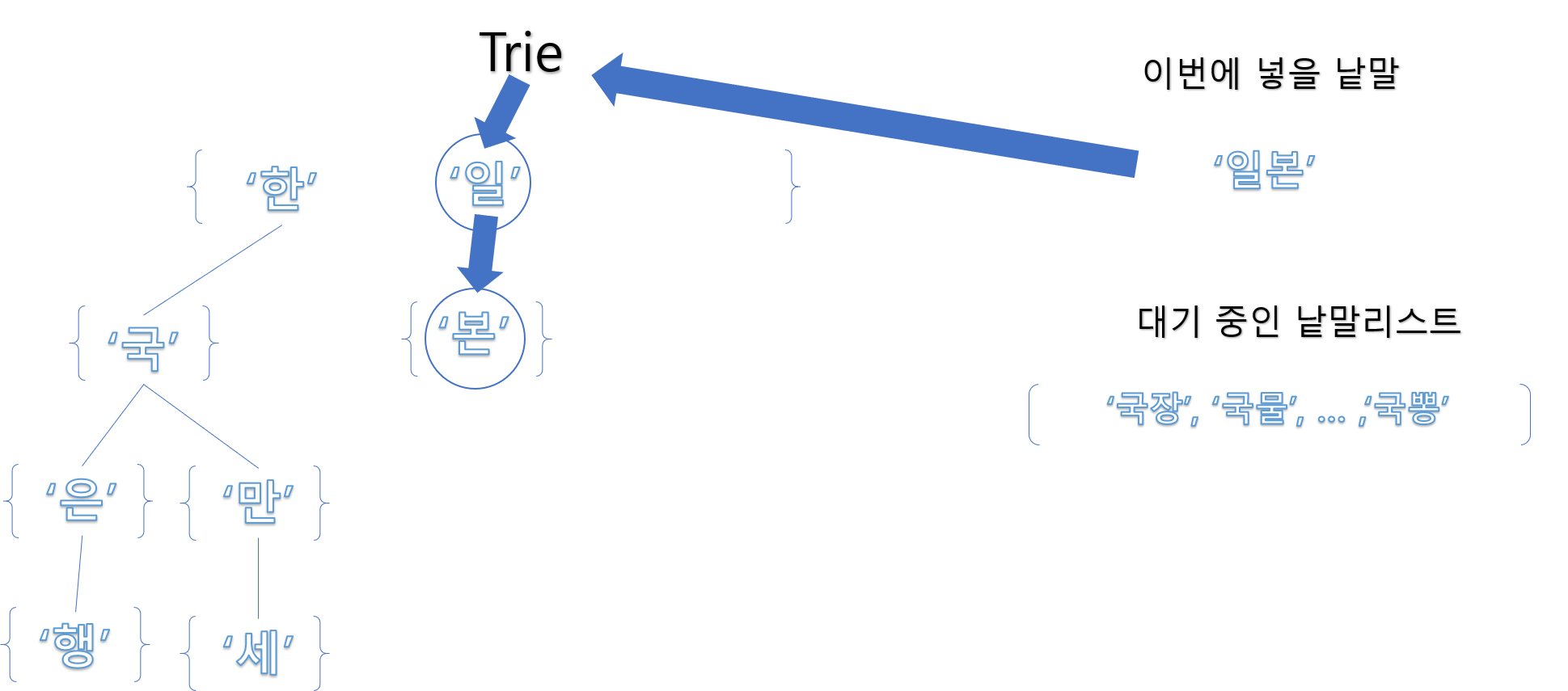
아래는 Trie를 만드는 과정 중 ‘일본’ 이라는 낱말을 넣는 차례입니다.
Trie를 다 만든 단계:
위의 과정이 모두 끝나면 아래와 같습니다.
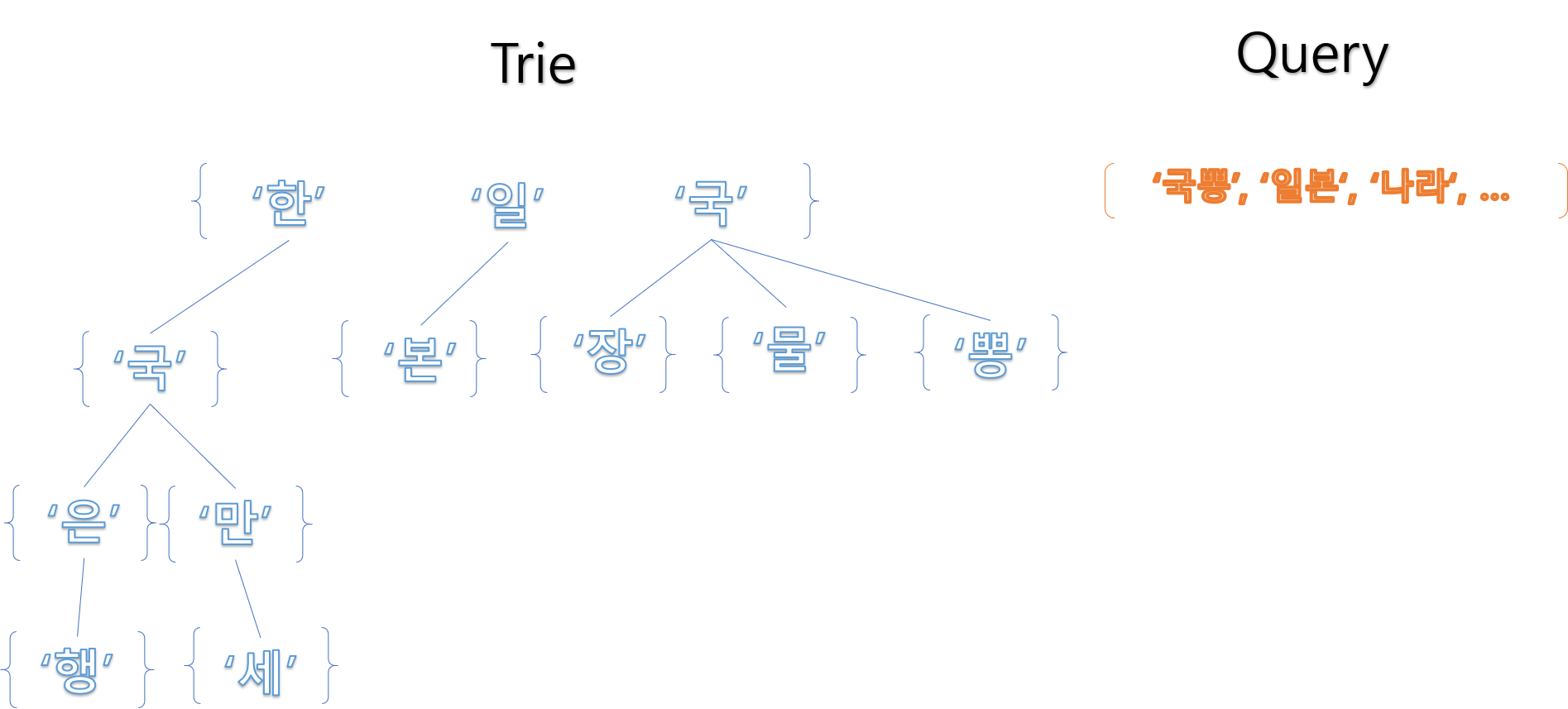
Query를 찾는 단계:
우리가 찾고싶은 쿼리는 ‘국뽕’이라고 한다면 먼저 ‘국‘을 가진 노드를 찾고
‘국‘에 해당하는 다음 노드로 넘어간다음, ‘뽕‘이라는 노드를 찾으면 됩니다
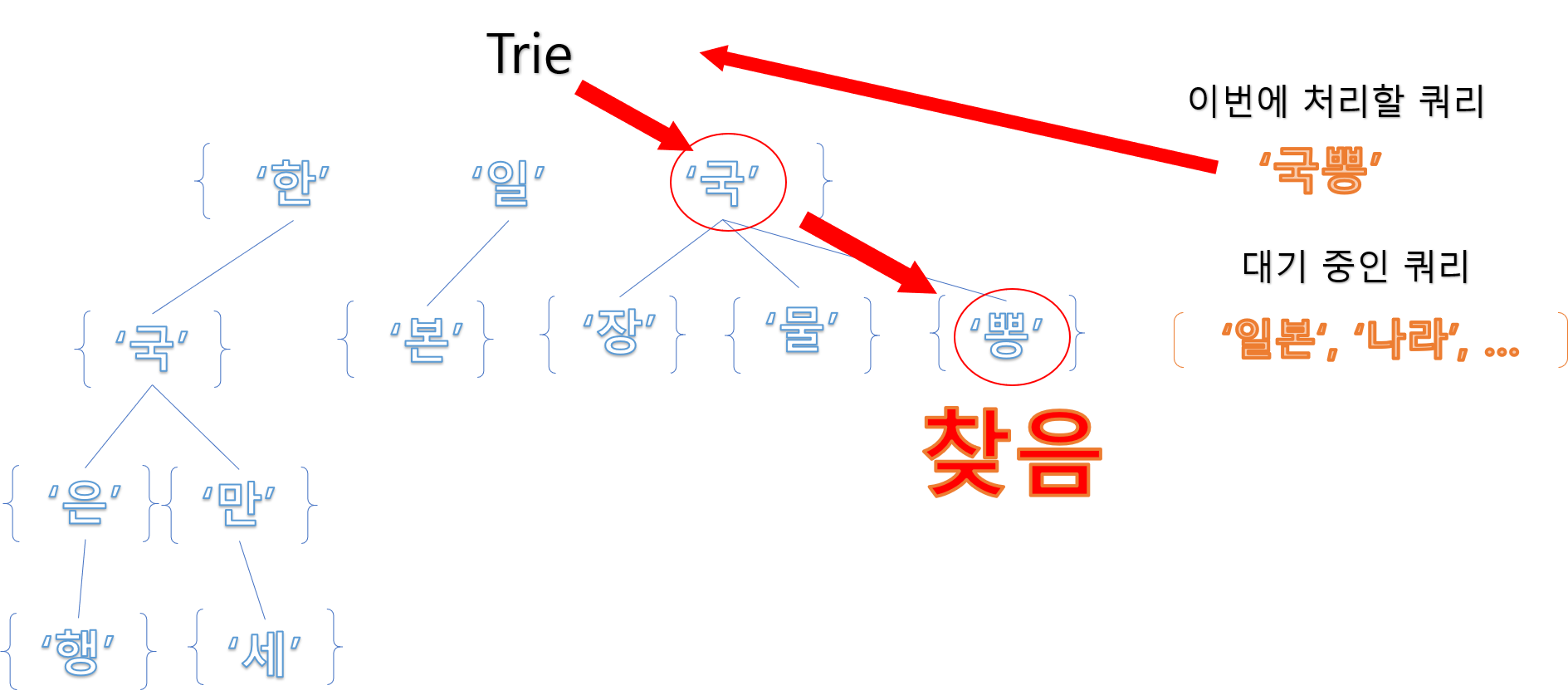
이번에는 ‘일본’이라는 낱말을 찾는 경우입니다.
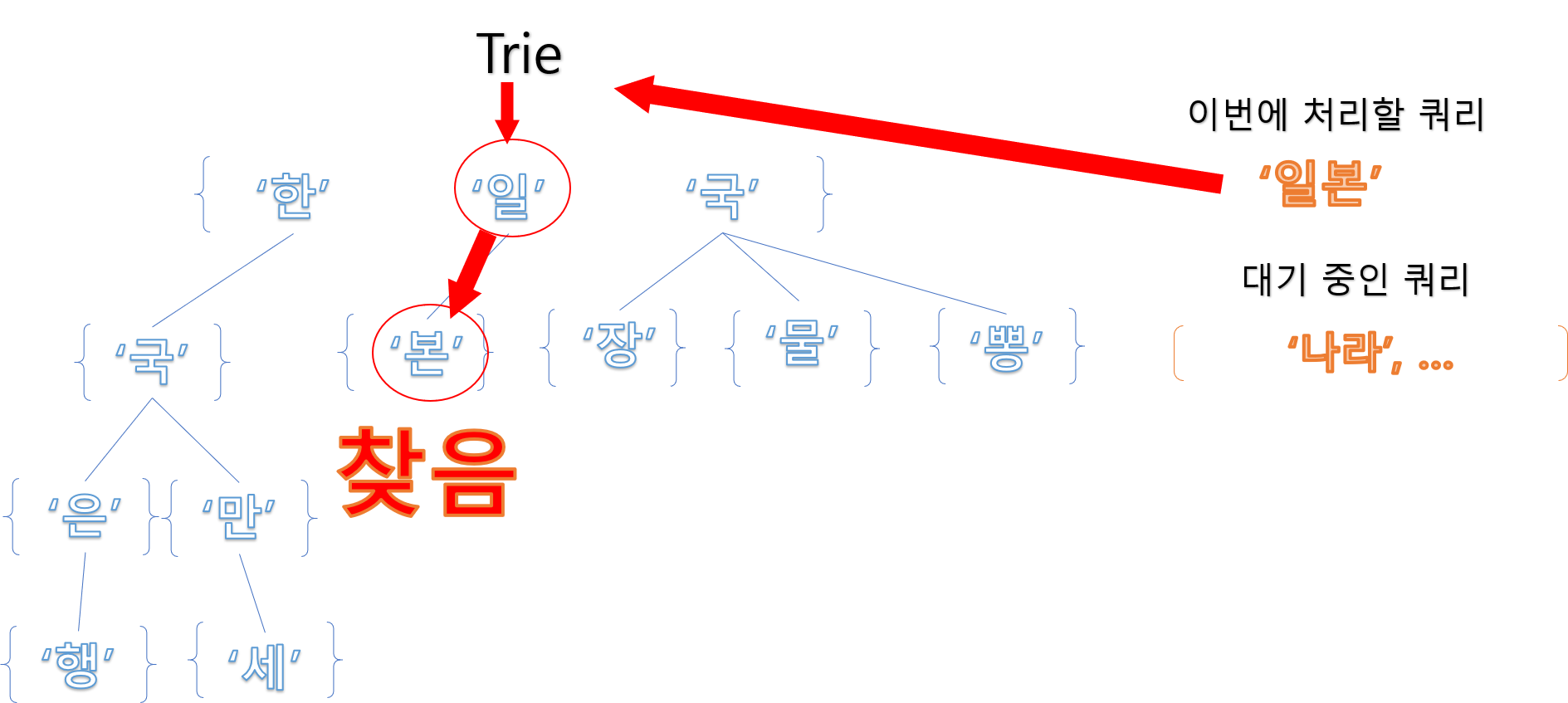
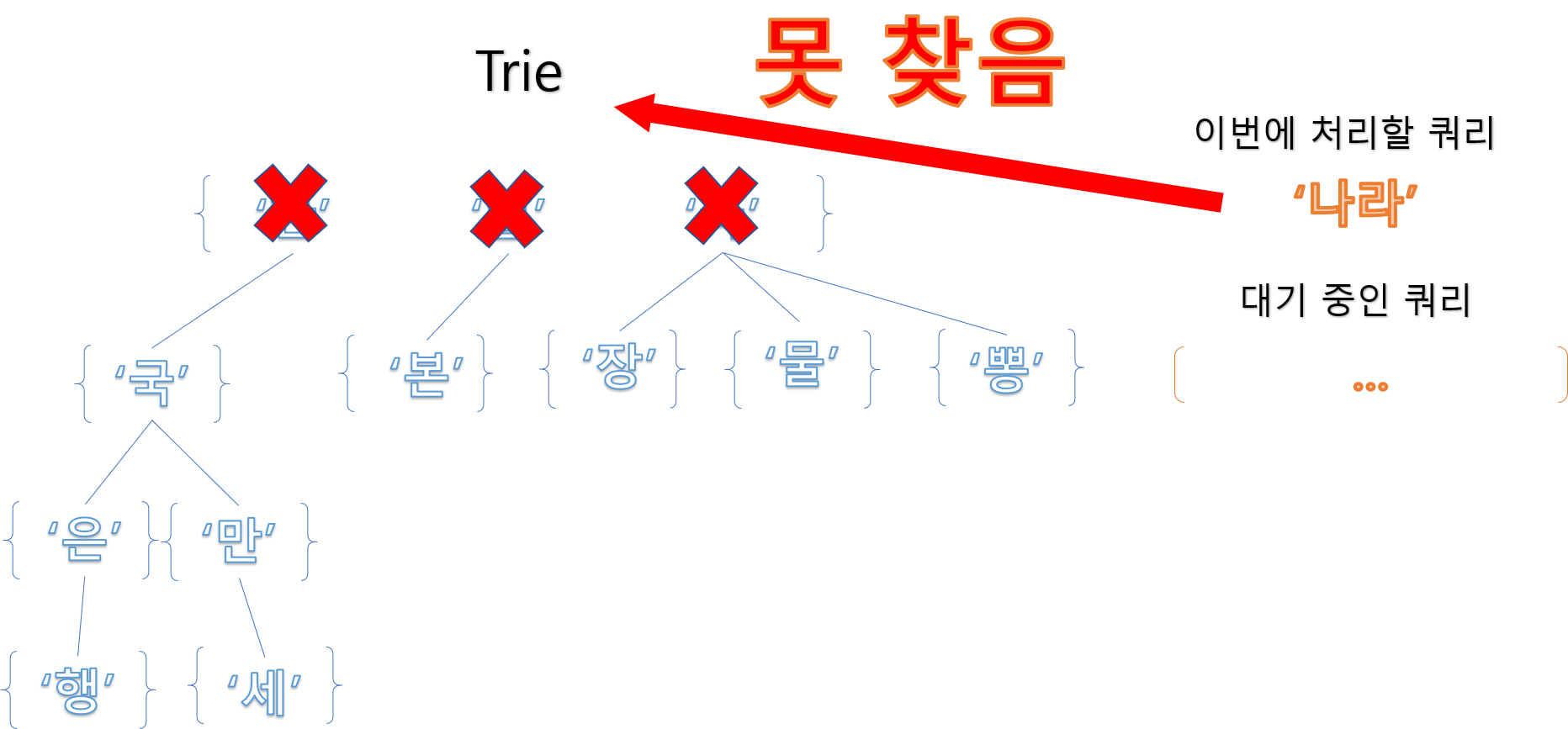
이번에는 ‘나라’ 라는 낱말을 찾는 경우인데, 첫 번째 노드부터, ‘나’ 라는 글자가
존재하지 않습니다. 따라서 여기엔 ‘나라’ 라는 낱말는 없다 라는 걸 바로 알 수 있습니다
트라이의 장단점
장점:
Query를 찾을 때, Brute-force를 이용하는 것보다 좋은 time-complexity를 가집니다.
특히, 처리하는 Query의 수가 많아지면 질수록 이 구조은 정말 유용합니다.
구현하는 것도 어렵지 않고 아이디어도 간단해서 여러 응용을 하기 좋습니다.
예로: Visted 같은 변수를 추가해서, 갯수를 추적하는 것도 가능합니다.
단점:
space-complexity면에서는 기존의 것보다 비효율적입니다.
대부분 구현과정에서 Map을 쓰게 되는데, 이 때 space가 꽤 듭니다.
쿼리가 워낙 적으면 오히려 시간이 걸릴 수도 있다.
일단 이 구조는 만들 때도 String hash를 하기 때문에 시간이 걸립니다.
따라서 쿼리 양은 되게 적고, 저장되어있는 단어는 상대적으로 많을 때
오히려 Brute-force한 것보다도 더 안좋은 execution-time을 가질 수도 있습니다.
실제 구현 by Python
구현 아이디어:
- linked-list
- Dictionary
- iteration
- Tree
Code:
class Trie:
def __init__(self):
self.root = {}
def insert(self, s):
cur = self.root
while s:
if s[0] not in cur: cur[s[0]] = {}
cur = cur[s[0]]
s = s[1:]
cur[0] = {}
def find(self, s)->bool:
cur = self.root;
while s:
if s[0] not in cur: return False
cur = cur[s[0]]
s = s[1:]
if 0 in cur: return True
else: return False